2020 Git
(Started 7/15/2020)
![]()
2020 Git(Started 7/15/2020)
|
|
Git is a source code control system for software developers.
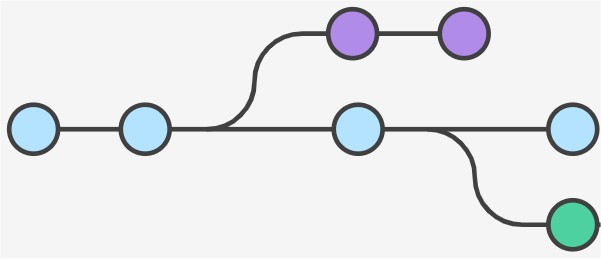
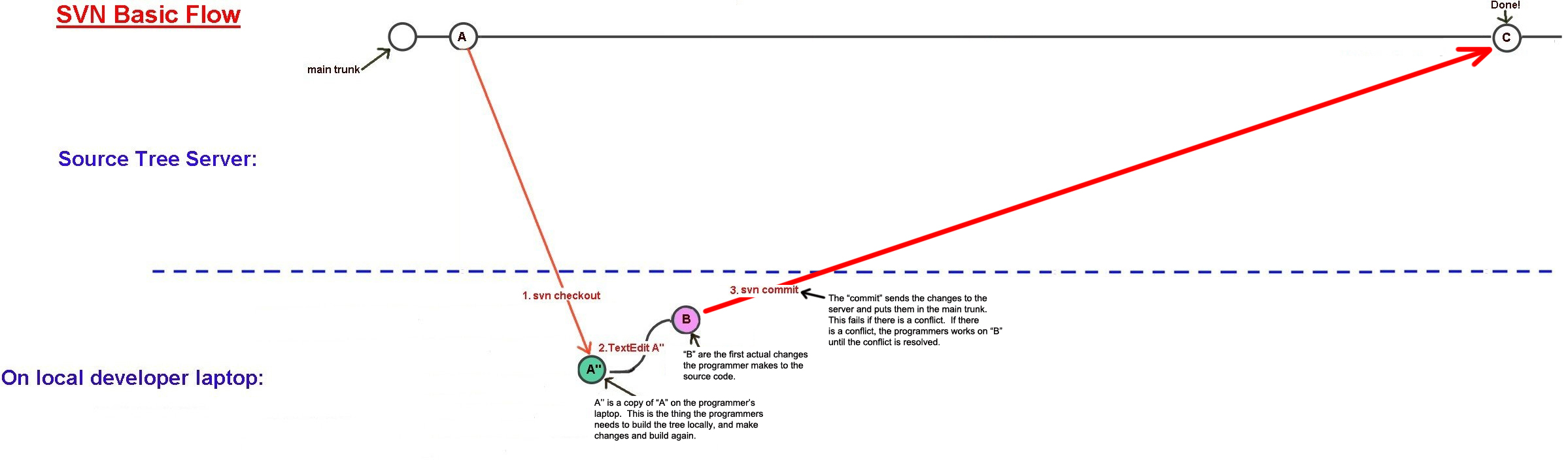
Below is the basic flow of all source code control. There is a server with the "main trunk" shared by all developers. The idea is to make a copy of the main trunk locally on a developer laptop, try out some changes and work on the code for a while, and then get the finished changes back into the "main trunk". Below is how this is done in the source code control system called "Subversion" (SVN), but it is pretty much the same in Perforce, CVS, and a number of other source code control systems I have used. Time flows from left to right. Click on any image below for a bigger version:
Ok, so GIT was invented in 2005, and achieves this same basic task. At the same time, GIT made the decision to introduce many extra manual steps and many extra "states" as seen below. Personally I don't find the extra states useful, but some programmers get REALLY excited about how great GIT is, for the first time in their life they are productive programmers while before GIT they just couldn't write software - their software would crash too much or required too much testing, or something. Personally I have never spent more than 1% of my total time (before GIT) dealing with whatever one of the 10 different source code control systems was used by the company where I worked. So it would be hard for GIT to save me more than 1% productivity. But it seems to make some other engineers happy.
Software engineers who like GIT tell me that they find each and every step below useful and it's super fun for them to spend a lot of time constantly playing with the source code control system in interesting ways. It's like a hobby. The harder and more complex it is to use just means it is a challenge to overcome, and solving complex challenges are fun! The people that really like GIT and get excited about this like to hop around between all of the states below in random order, and GIT allows you to do this.
For me, a source code control system is about exciting as a basic hammer. Source code control is an extremely useful and necessary tool, we have had it for years, and it worked. The whole software industry survived just fine without GIT for 32 years (GIT was invented in 2005, while Unix had SCCS as far back as 1973). I've worked at companies like Apple, Silicon Graphics, HP working on source bases with 20,000 other software engineers checking into the same tree, and never had any issues or spent more than 1% of my total time dealing with the source code control system to get my job done. But now we have GIT, and it's really clunky and slow, and importantly it lost some of the best functionality I used before in all the OTHER systems.
So here we go, below is the basic flow we use at Backblaze to modify one source file. The "modification" is the "B" labeled bubbles. Time flows from left to right. Click on any image below for a bigger version:
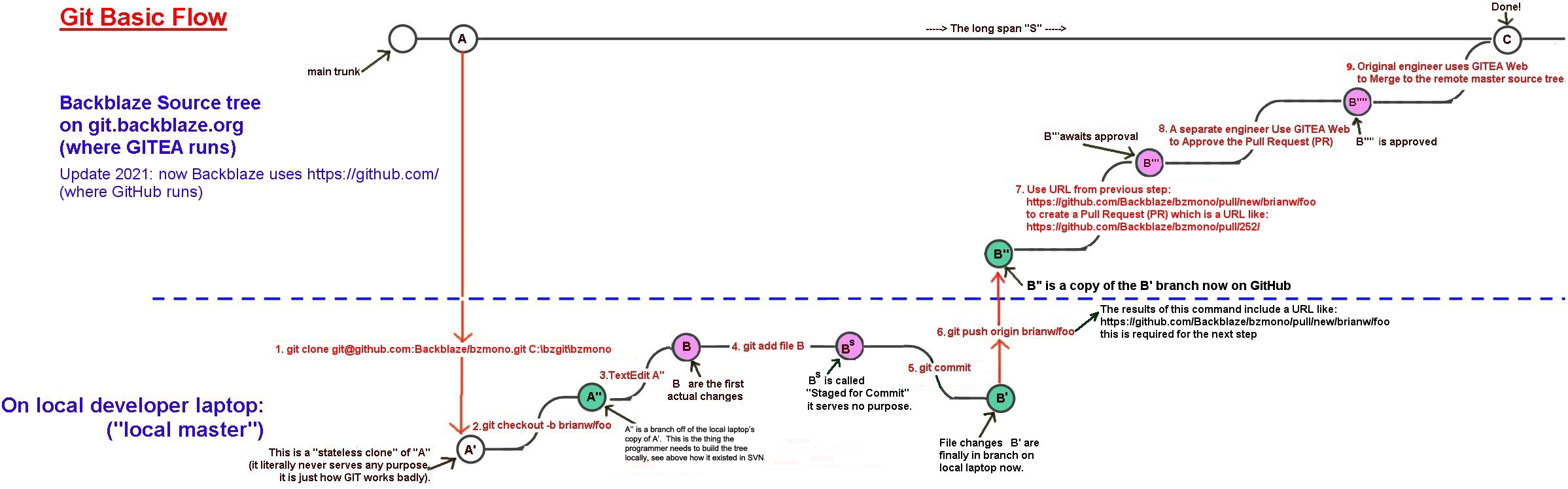
So yeah, it's definitely complicated.
In the flow above, you can see how many more steps it takes with Git to get the new modified code from the programmer's laptop (state "B") into the main trunk (state "C"), plus it involves waiting a long time for various steps to complete like the code reviews. You can't get work done while you are waiting for each step. So this discourages frequent checkins. For example, since Git requires PR and code reviews, it means whenever I do a checkin I must stop working until another engineer wakes up (if I did the commit at 10pm at night for example), gets my message, reviews the code, and approves it. Then I have to merge that change, then checkout a new tree and start working again. This means it's best to just hold off on checking anything in for a very long time, until the code is finished and complete, then do 1 checkin so you don't have to do all these steps over again.
Over the years I've seen some programmers (like me) like to work by making small, controlled changes and get them into the main trunk frequently. These small frequent "commits" into the main trunk avoids a really big "conflict" where I have made thousands of lines of changes in hundreds of files, and have to throw them away because another programmer changed the underlying code and my code is incompatible with the other programmer's code. In this mode of working, let's say you check into the tree once per hour. The most work you will lose because of a conflict is 1 hour of work. Now other programmers I have worked with are very successful doing it a DIFFERENT way: they spend months of time working on a feature in their own tree, happily stable during that time because they don't update their tree. Then they are faced with a large "merge step". Plus it can be even worse than that. If their code is incompatible with changes other programmers have made then they have to DISCARD ALL THEIR WORK AND START OVER. So instead of discarding their work and doing it correctly I think these programmers just do whatever it takes to force the changes into the incompatible main trunk. I suspect they trust the automatic merging of their new code by the tools. While this dangerous and error prone, I've seen these programmers be successful. I think some of it is they check in code even if it breaks things or introduces bugs, and later eventually the bugs are found and fixed, so it all works out eventually. I think GIT makes these "stay out of the main trunk a long time" programmers happier, because it has lots of features to support this mode of working.
To illustrate this difference in programming style (frequent small commits each day vs one monolithic commit at the end of some period of time like a week or a month), let's say a programmer is supposed to fix 1 bug per programming day and there is a code freeze every Friday at 5pm.. I fix one bug on Monday, commit the fix to the main trunk for that one bug at the end of Monday. Tuesday I check out a fresh tree and do this same procedure for the second bug, etc. But these other programmers prefer to fix 5 bugs in 5 branches in one week but don't want to "commit" them to the main trunk for some mysterious reason. So they hold all 5 bugs in different branches locally on their laptop, then on Friday they do 5 merges a few minutes before the same weekly code freeze. Git supports this, because you can switch between 5 different branches, and work on bug #1 on Monday but hold the fix in their local tree (not committing the changes to the main trunk), then on Tuesday the programmer branches from their original tree again works on bug #2, finishes that bug, but does not "commit" it to the main trunk, etc. The older source code control systems don't have this support for working a long long time from a very old clone of the source tree and avoiding the "commit" until the last second. The older systems never bothered me because I prefer frequent checkins anyway. But some programmers were always frustrated by being forced to finish one bug and commit it into the main trunk before working on the next bug, so Git makes them happier.
I am not sure why some programmers prefer Git and these enormous merge steps, and if
you have any ideas you should contact me at:
![]() and I'll put
your comments here. I think Git tricks you into thinking the "main trunk"
is not a place you can do incremental fixes, it is for "other people" and not
you the programmer. So you create branches for yourself on the server side like state B''
that act like main trunk in some ways (it's on the server side) but doesn't
involve the same emotional commitment as doing the same identical commit to
main trunk. My issue with this is your
code has to go into main trunk or it cannot be in the final product. There
is no way around this. The code MUST end up in the same final place.
Monolithic checkins to the main trunk are a form of procrastination.
and I'll put
your comments here. I think Git tricks you into thinking the "main trunk"
is not a place you can do incremental fixes, it is for "other people" and not
you the programmer. So you create branches for yourself on the server side like state B''
that act like main trunk in some ways (it's on the server side) but doesn't
involve the same emotional commitment as doing the same identical commit to
main trunk. My issue with this is your
code has to go into main trunk or it cannot be in the final product. There
is no way around this. The code MUST end up in the same final place.
Monolithic checkins to the main trunk are a form of procrastination.
Another theory I have is that programmers that prefer these Git monolithic commits don't understand the "tricks" I use to do incremental checkins to the main trunk. For example, if I add a function to the main trunk but it is not called from anywhere, I'm using the main trunk as a place to do incremental work that is COMPLETELY SAFE. I think programmers are afraid to put incremental new functions in the main trunk because they put the main trunk on a pedestal and say it always has to be PERFECT and not contain a function (not called from anywhere) that contains half written code or a bug. These programmers are letting PERFECT be the enemy of PROGRESS.
Another thing that has become clear to me (not just a theory) is that the code review process means you MUST do monolithic commits. The code review won't "pass" (will be rejected) 100% of the time for small changes that are half done but not called from anywhere. A programmer is forced to finish the code before the code review will pass. This forces programmers to stay out of the tree until the feature or bug fix is 100% finished, polished, and tested - that's a monolithic checkin. To prove this is the case, I proposed "mandatory approvals" for code reviews. This is where all code is reviewed and feedback is given, but the decision on whether or not to allow it into the tree is reserved for the person writing the code, not the code reviewer. It was rejected universally at Backblaze. All programmers want to prevent code from the OTHER way of working from being checked into the tree until it is finished. They feel this "rejection until finished and perfect" has no downsides, because they think EVERYBODY loves monolithic checkins like the way they like to work. But the downsides of monolithic checkins are very real for programmers like me who prefer to work with smaller, frequent checkins.
Another theory I have is that at some point, programmers that like monolithic checkins just gave up on the idea that the merge will ever go smoothly. If every time they force a merge the tree breaks and can't be built, they want all of that to occur at the same time ONCE PER WEEK, and not break the build for the other engineers 5 times a week. I rarely break the build because with small changes I can update my local copy and compile it there to know it works, so this isn't a concern to me.
In SVN or Perforce (a different source code control system), when a software engineer was at node "B" in either diagram, they could type a command and get a summary of the differences between node "B" and "C". In other words, I could look into the future and know what merges lay ahead on the long and dangerous path from "B" to "C". This was an opportunity to correct problems with the merge IN ADVANCE. I wrote the tool "bzdiff" to wrap commands on Subversion to copy the format from Perforce that I found extremely useful and concise. Here is an example output from "bzdiff -s":
These files are interesting:
M bzapps/bztransmit/bztransmit.cpp
M bzapps/bztransmit/bztransmit.h
! bzbase/BzVersion.cpp
done.
This can be read as: "bztransmit.cpp and bztransmit.h have been modified locally on the programmer's laptop" (state "B" in the above diagrams) and there will be no conflicts in the future during a merge, and "BzVersion.cpp has been modified locally however there will be a CONFLICT during merge". That "heads up" is critical, I know to go investigate and fix my local copy to be compatible BEFORE wasting the 5 additional steps it will take to get my new code into the "main trunk". I don't want to waste all that time and effort if it won't work anyway. The complete decoder ring for any "issues that will arise during checkin" looks like this:
U file needs to be updated (newer version exists in svn) M local file has been modified, needs to be checked into svn ! conflict -> local file has been modified, but tree has newer version + svn has not heard of this file (do "svn add file" to add it) - file has been removed from svn (do "svn update" then remove local file) A file has been "added" to svn, but not "committed" R file has been "removed" from svn, but not "committed"
PLEASE DO NOT SAY THE ANSWER IS "git status". That is wrong. That is the differences between state A'' and B, not the differences between state "B" and state "C".
All done.
![]()