- by Brian Wilson, 8/30/2021
![]() if
you have comments or suggestions.
if
you have comments or suggestions.
Goals of This Document:
Specify the UI and some
thoughts around implementation of how to support Vanity Urls (also called "custom domains",
also called "CNAME" support) in
B2.
What is the Feature?
The ability for a B2 customer to have these a URL of type #4 below serve the
same content as all the other URLs:
Friendly URL:
https://f003.backblazeb2.com/file/catsanddogs/cutedogs/cute_puppy.jpg
S3 URL:
https://catsanddogs.s3.eu-central-003.backblazeb2.com/cutedogs/cute_puppy.jpg
Vanity URL: https://sharefiles.kookbeach.com/cutedogs/cute_puppy.jpg
A "vanity URL" is one term for a custom domain. B2 already has functionality to fetch any of the URLs #1 - #3 above, this feature is implementing URL #4.
Isn't this possible already?
Not by using Backblaze B2 alone. It is possible to configure 3rd party
systems on top of B2, like put a CDN such as Cloudflare in front of a B2 bucket to
kind of achieve the same END USER result, but it is difficult, error prone, and
not many people have ever pulled it off, and this isn't an option for regular
people. Configuring a CDN is something only professional IT people do, and
then you deal with two separate companies, including the bills from two
companies.
Is this building a CDN?
No. A CDN is something completely different. In the past we have
used a CDN as a total hack to achieve this for certain large customers, and this
has brain damaged the way people think. This
is just another URL to access the same one file. We already had 3 URLs to
access a file, we want a 4th URL to access a file. It doesn't change the
performance like a CDN does, it doesn't increase or decrease uptime like a CDN,
it doesn't do "edge caching" (geography based caching) like a CDN does, it
literally has nothing at all to do with a CDN. Nothing.
Is this building a Hosting Feature?
No. Hosting is something completely different. This is just another
URL to access the same one file. This has zero to do with hosting.
This is not hosting any more than the S3 URL is "hosting" or the friendly URL is
"hosting" or the Native URL is "hosting". Why would you think serving up
another URL is "hosting"? I feel you aren't thinking clearly.
Why Do This Feature?
There are a couple of reasons to do this feature:
Make more money.
Customer have requested it.
Example A:
https://www.reddit.com/r/backblaze/comments/p5eeue/update_on_vanity_subdomain/
Example B:
https://www.reddit.com/r/backblaze/comments/s80dx5/presigned_urls_not_working_with_cloudflare_cname/
Example C: For reputation purposes: when f001.backblazeb2.com
is on a blacklist.
Search in Backblaze slack for
matthew@alderongames.com or
b2 account id: 7445d3b1f7c9,
ZenDesk:
https://backblaze.zendesk.com/agent/tickets/744630
Example D: in a note to BrianW on reddit on 1/23/2022, a
customer writes:
"I found this post here
https://www.reddit.com/r/backblaze/comments/p5eeue/update_on_vanity_subdomain/
& also read your proposal you wrote here
https://www.ski-epic.com/2021_supporting_vanity_urls_in_b2/index.html
& I was wondering if there are any updates on this? Currently trying to
map
the S3 domain to a own subdomain
but with no luck." -- reddit identity ending in "rfive".
Make it really easy to do this for customers.
Customers don't like hard to use products. Customers like easy to use
products.
Support CloudFlare customers better and more easily.
Evidence from customer comment here:
https://www.reddit.com/r/backblaze/comments/p5eeue/update_on_vanity_subdomain/hb4g468/
"I would also note that this feature would make CDNs much easier to use. For
example with Cloudflare, instead of all the frankly weird page rule stuff
discussed at
https://help.backblaze.com/hc/en-us/articles/217666928-Using-Backblaze-B2-with-the-Cloudflare-CDN
, you simply point photos.example.com to the B2 bucket hostname, and it just
works (plus your bucket name is properly hidden behind Cloudflare, instead
of leaked as part of the semi-vanity URL)."
What is This Feature NOT DOING?
This feature WILL NOT implementing hosting, and WILL NOT be implementing a CDN.
That is not a goal. This is just one more URL to a file, that's all.
How A Customer With Their Own DNS Configures This:
BrianW uses "hover" as the domain registration for kookbeach.com (kookbeach.com
is a vanity domain, for a vanity URL). So here
are the steps after logging into hover.com:
PLEASE NOTE: the name of the B2 bucket I'm configuring with a Vanity URL is "catsanddogs", and the vanity URL is https://sharefiles.kookbeach.com
Click "My Account" in upper right, and select "Control
Panel" -> a list of "domains" will be shown
Click on "kookbeach.com" on the left.
You should be on the "Overview" tab. Click "Edit" by
Nameservers and make sure they are pointed at the hover DNS servers
ns1.hover.com and ns2.hover.com
Click the "DNS" tab.
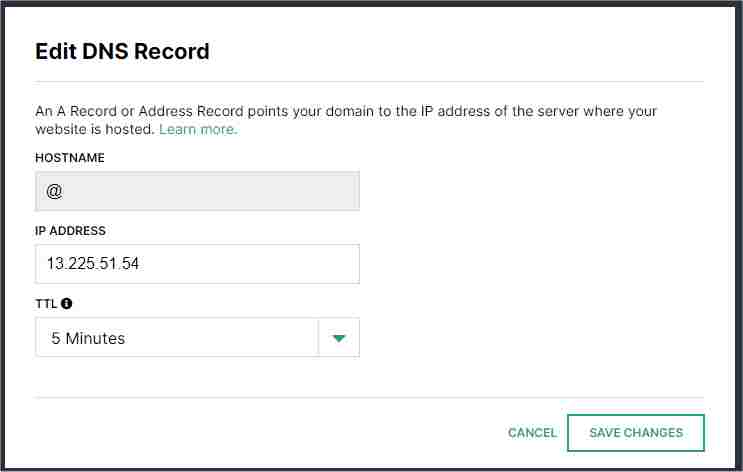
MAYBE NOT NECESSARY -> Add an "A Record" to point random IP
address like 13.225.51.54 (that's where ski-epic.com resolves to)
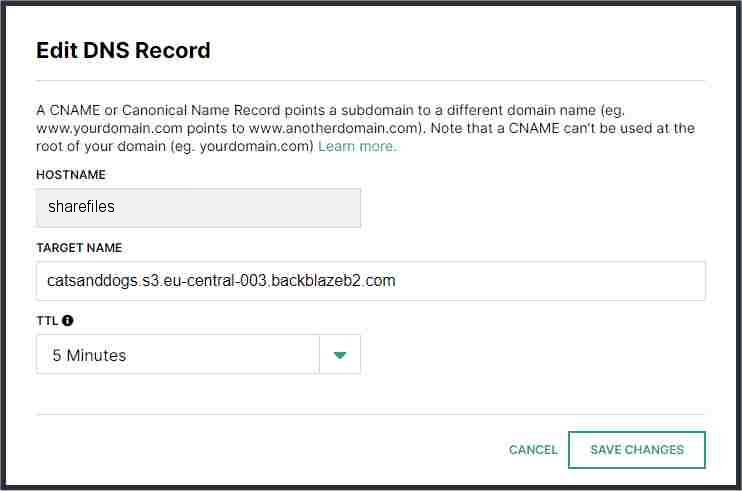
Add a "CNAME Record" to point sharefiles.kookbeach.com to
catsanddogs.s3.eu-central-003.backblazeb2.com
(NOTE: this may work fine, but to generate the certificate it may be
required that this is an A record. This needs to be tested.)
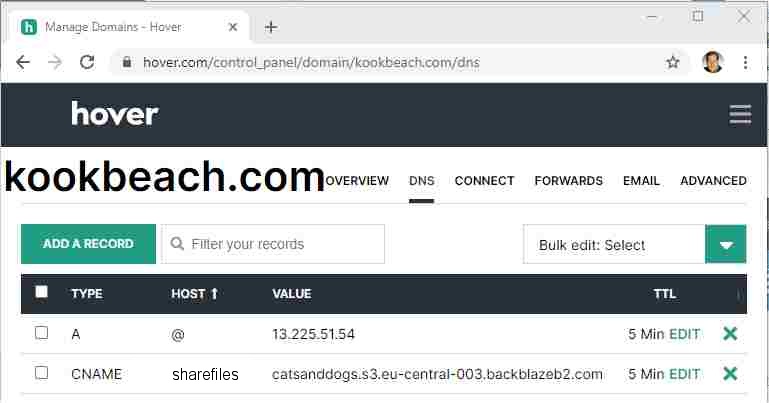
Now the DNS tab should look like this:
Ok, so at this point you are all finished configuring your DNS. Try "ping sharefiles.kookbeach.com" (it might take a few hours for this to work because DNS propagation is slow) and it should say:
% ping sharefiles.kookbeach.com <-- type this in a command prompt on Windows Pinging catsanddogs.s3.eu-central-003.backblazeb2.com [45.11.37.254] with 32 bytes of data: Reply from 45.11.37.254: bytes=32 time=122ms TTL=45 Reply from 45.11.37.254: bytes=32 time=122ms TTL=45 Reply from 45.11.37.254: bytes=32 time=122ms TTL=45
And also, if you try "ping catsanddogs.s3.eu-central-003.backblazeb2.com" it
says the same IP address:
% ping catsanddogs.s3.eu-central-003.backblazeb2.com <-- type this in a command prompt on Windows Pinging s3.eu-central-003.backblazeb2.com [45.11.37.254] with 32 bytes of data: Reply from 45.11.37.254: bytes=32 time=384ms TTL=45 Reply from 45.11.37.254: bytes=32 time=348ms TTL=45 Reply from 45.11.37.254: bytes=32 time=421ms TTL=45
That's it! Those are all the changes required OUTSIDE of Backblaze.
GUI Changes to Backblaze Web Interface:
We need the ability to specify that this bucket accepts a particular CNAME.
Here is what that would look like:
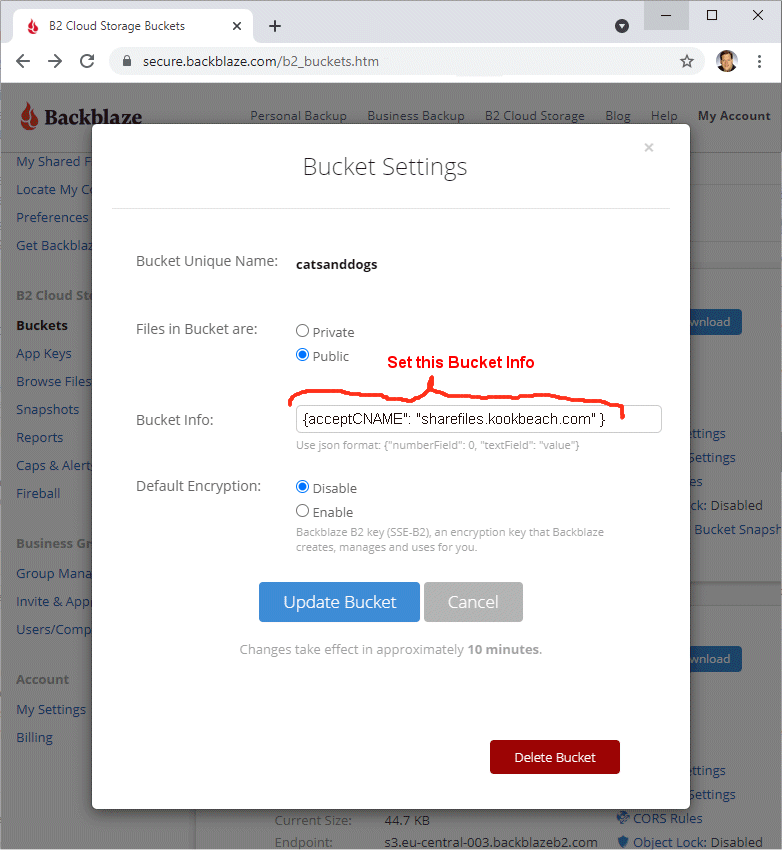
Now, when the customer pops up the "Details" information for any file in that bucket, there is one additional URL added. See below:
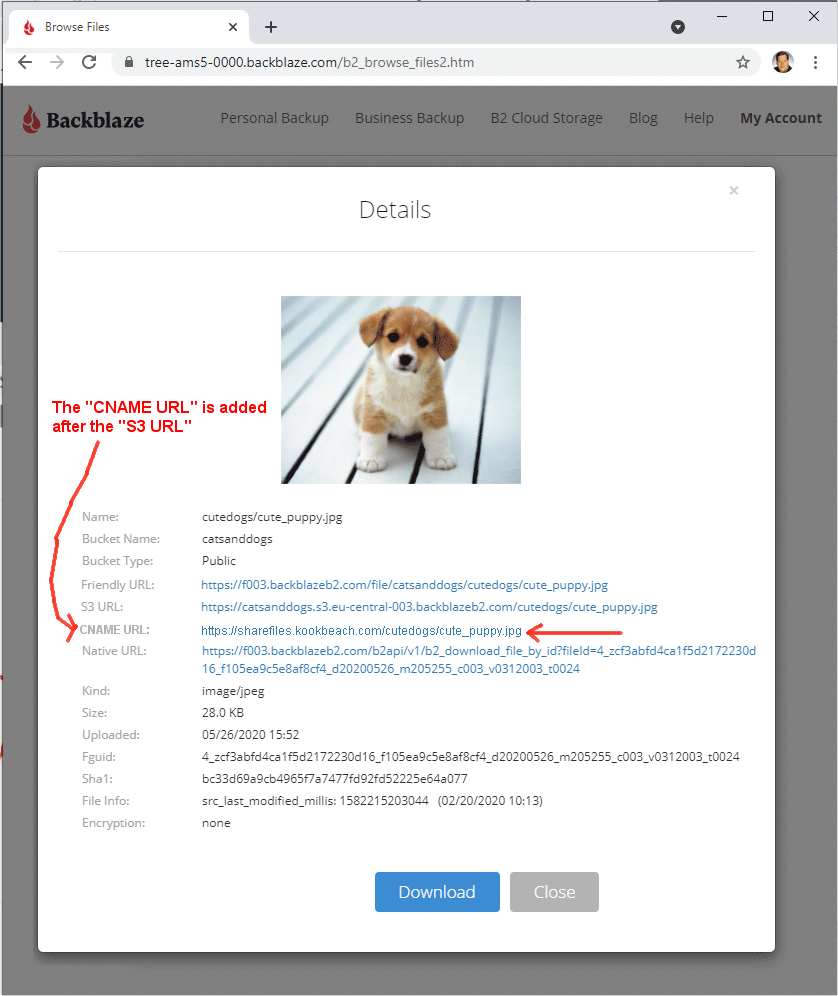
That is it for GUI changes.
Store the mapping of "acceptCNAME" to "S3_Domain" in
cluster specific Cassandra in Table called "VanityUrlMappingTable":
We need to store the acceptCNAME mapping in two places, and we need to keep them
in sync:
In the BucketInfo. This code is already completely finished, buckets can store and retrieve their BucketInfo structure which is JSON.
We need to maintain a mapping of ALL of the vanity URLs to bucket S3 URLs and bucketIds in one table in the cluster specific Cassandra. The table might look like this:
VanityUrlMappingTable: (found in cluster specific Cassandra, so these are all in the "eu-central")
| acceptCNAME | S3_Domain | bucketId |
| sharefiles.kookbeach.com | catsanddogs.s3.eu-central-003.backblazeb2.com | 5c5a30101287102070b00013 |
| downloads.larryphotography.com | larrybucket.s3.eu-central-003.backblazeb2.com | 2070b000135c5a3010128710 |
| tom-jones-meatpackers.com | porkloin.s3.eu-central-003.backblazeb2.com | 0002070b135c5a3028710101 |
The idea is that various code on the system (like the API servers) need to look up one of the "acceptCNAME" and quickly get returned the "S3_Domain" that is associated with it. THIS TABLE WILL NOT BE VERY LARGE, it is only expected to be 100 vanity URLs (100 rows in the table called VanityUrlMappingTable) per cluster in the first year.
To keep #1 and #2 in sync, whenever any customer changes their
BucketInfo, and also has an "acceptCNAME" in that BucketInfo, it is also set in
this VannityUrlMappingTable. The change to BucketInfo is rejected if it
fails to be set in VanityUrlMappingTable for whatever reason.
IMPLEMENTATION CHOICE: one idea is that we do NOT create a new "custom" table
inside of Cassandra like above. Instead, like we sometimes do for the
server side implementation of B1 products, we could simply create a
brand new private B2 bucket in our reserved namespace called "bzvanityurlmapingtable".
INSIDE of that bucket would contain files named these things to represent the
above table:
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/sharefiles.kookbeach.com/myS3domain.txt
(this file would contain the string
"catsanddogs.s3.eu-central-003.backblazeb2.com")
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/sharefiles.kookbeach.com/myBucketId.txt
(this file would contain the string "5c5a30101287102070b00013")
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/downloads.larryphotography.com/myS3domain.txt
(this file would contain the string
"larrybucket.s3.eu-central-003.backblazeb2.com")
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/downloads.larryphotography.com/myBucketId.txt
(this file would contain the string "2070b000135c5a3010128710")
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/tom-jones-meatpackers.com/myS3domain.txt
(this file would contain the string
"porkloin.s3.eu-central-003.backblazeb2.com")
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/tom-jones-meatpackers.com/myBucketId.txt
(this file would contain the string "0002070b135c5a3028710101")
In this fashion, we would have the fast lookups we need, without a "custom" Cassandra table. Stored INSIDE of B2.
What The Underlying Functionality Does:
There are three things that have to be implemented.
The API/Download Servers need to accept requests to
https://sharefiles.kookbeach.com and this
functionality is called "Host Header".
Click
here to see that in the RFC. Right now the API/Download servers at
https://f003.backblazeb2.com are
expecting a Host Header of:
"Host=catsanddogs.s3.eu-central-003.backblazeb2.com:443" and it rejects
anything that doesn't look like that. This code needs to be modified
to accept posts if the "acceptCNAME" is set on the bucket being accessed.
It might also be interesting to look into "Server
Name Indication" but it may not be necessary. Here are some places
in our current Java code to look:
- bzmono/www/java/src/com/backblaze/modules/s3Compat/b2_api/guts/S3HostnameParts.java
- object "S3HostnameParts"
- bzmono/www/java/src/com/backblaze/modules/s3Compat/b2_api/servlet/S3CompatDispatcher.java
- rejects HTTPS request if "Host Header" is not correct.
When a request comes in for
https://sharefiles.kookbeach.com/cutedogs/cute_puppy.jpg then the API/Download
server needs to serve up the same thing it served when it gets the request
for
https://catsanddogs.s3.eu-central-003.backblazeb2.com/cutedogs/cute_puppy.jpg
Backblaze needs an HTTPS certificate for
https://sharefiles.kookbeach.com through
the "HTTP-01
ACME challenge"
Of these three steps, I believe #1 and #2 are fairly
straightforward. I also think we can build #1 and #2 to get that part
working, then tackle #3 once everything else is working correctly. So the
section below here is dedicated to how to do #3...
How to implement #3 above:
There is a beauty to getting a LetsEncrypt certificate from the "HTTP-01
ACME challenge". Here is a quote from
https://letsencrypt.org/how-it-works/:
"The objective of Let�s Encrypt and the ACME protocol is to make it possible to set up an HTTPS server and have it automatically obtain a browser-trusted certificate, without any human intervention. This is accomplished by running a certificate management agent on the web server."
Quick explanation of the HTTP-01 ACME challenge: to prove the Backblaze API/Download servers have the "rights" to serve up content over SSL/HTTPS, the API/Download servers contact the LetsEncrypt servers with a request for an HTTPS certficate for sharefiles.kookbeach.com like this, and the LetsEncrypt servers respond with the name of a file to write out to a certain location, with certain signed contents:
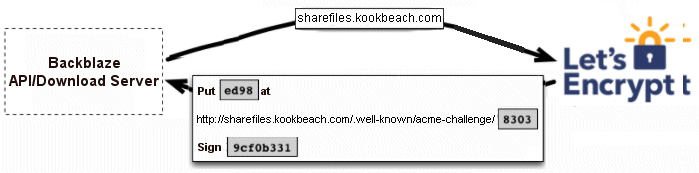
After the Backblaze Download/API servers create that file in the user's bucket and are willing to serve it up on HTTP (notice it is not HTTPS), then LetsEncrypt fetches the contents of http://sharefiles.kookbeach.com/.well-known/acme-challenge/8303 (notice that is not HTTPS yet) and verifies that the challenge was completed correctly which proves the Backblaze API/Download servers are authorized to do certificate management for sharefiles.kookbeach.com and that's the concept of the HTTP-01 ACME challenge.
So to implement this, here are some things it will involve.
First, we have to turn on HTTP access (no SSL) to the API/Download servers, because there is a chicken and egg problem: how do you get an SSL cert if you don't have one to communicate with? When requests come into port 80 (HTTP) the Java code should be carefully written to only accept requests that appear to be LetsEncrypt requests for vanity domain certs. So for example, if "https://sharefiles.kookbeach.com" is the only vanity domain enabled in cluster 003, then ONLY requests to http://sharefiles.kookbeach.com/ (port 80, no SSL, not HTTPS) the Java code should only respond/allow that vanity domain on port 80, and furthermore only this URL should be allowed: http://sharefiles.kookbeach.com/.well-known/acme-challenge/<TOKEN> on HTTP on port 80. Furthermore, this is ONLY on the API/Download servers in the cluster that this bucket is in.
The API/Download servers all need to have the program "certbot" installed. To install certbot on Debian, an admin types these commands:
# apt-get install software-properties-common # add-apt-repository apt-get install certbot # apt-get update # apt-get install certbot
This should be translated into our Backblaze system of however we get software installed on API/Download systems.
Ok, so we ALSO need an "internal-only accessible Java servlet" written. There are examples of this in the way the cluster authority interacts with Yoda for example, or the cluster authority interacts with the restore servers. These are *NOT* publicly accessible from the internet Below is the pseudo-code for the Java Servlet that fires when a URL https://localhost/write_certbot_verify_into_bucket is fetched:
public static boolean write_certbot_verify_into_bucket(String certbot_token, String certbot_domain) throws WebApiError {
Step 1: Look up hguid and S3_Domain from VanityUrlMappingTable using the passed in argument "certbot_domain" as the row to lookup. The Table is found in the cluster specific cassandra (see description elsewhere in this document).
String hguid;
String theS3domain;
.... do the Cassandra lookup
here, and the values discovered are seen below ...
hguid="5c5a30101287102070b00013"
theS3domain="catsanddogs.s3.eu-central-003.backblazeb2.com"
Step 2: Store the certbot_token
in B2 so that it appears here if fetched from either location (notice one of
these is "http" with no SSL):
https://catsanddogs.s3.eu-central-003.backblazeb2.com/.well-known/acme-challenge/<value
of certbot_token>
http://sharefiles.kookbeach.com/.well-known/acme-challenge/<value
of certbot_token>
return true;
} /* end of
write_certbot_verify_into_bucket */
We also need this one line shell script to exist on all API/Download servers somewhere. This is a "hook" run by certbot, for documentation see: https://eff-certbot.readthedocs.io/en/stable/using.html#third-party-plugins
#!/bin/bash # Put this script in file /path/to/http/authenticator.sh # # This next line is commented out, but it is an example of how to use the values normally # echo $CERTBOT_VALIDATION > /var/tmp/.well-known/acme-challenge/$CERTBOT_TOKEN # # We need to get from this shell script into the Java code on this server # so we trigger a URL on our local API server with some arguments to go # do things for us like this: # bzhelper -fetchurltofile http://localhost/write_certbot_verify_into_bucket?certfile=$CERTBOT_TOKEN&certdomain=$CERTBOT_DOMAIN&certvalidation=$CERTBOT_VALIDATION # # In Java, this "write_certbot_verify_into_bucket" servlet that # runs on the API server and the API server writes the ACME challenge into the # actual bucket so that requests to: # http://sharefiles.kookbeach.com/.well-known/acme-challenge/$CERTBOT_TOKEN # from ANY API/Download server can retrieve that file! This is because API/Download # servers are load balanced and we cannot be sure which will get the verification fetch
After that is done and the API/Download servers have certbot available to them, then when a customer configures the bucket to contain properties on the bucket of { "acceptCNAME": "sharefiles.kookbeach.com" } then the Java code runs this command to get a valid cert for sharefiles.kookbeach.com:
# certbot certonly --manual --manual-auth-hook /path/to/http/authenticator.sh -d sharefiles.kookbeach.com ALTERNATIVELY FOR MULTIPLE DOMAINS: # certbot certonly -d kookbeach.com -d sharefiles.kookbeach.com --manual --preferred-challenges=http ALTERNATIVELY FOR MUTLIPLE DOMAINS: SOURCE: https://ddreset.github.io/softwaredev/2019/07/26/Make-SSL-Certificate-for-AWS-S3-Website-with-Let's-Encrypt-and-Auto-Renew-It.html
That is it, the valid SSL/HTTPS cert will appear in this folder:
# ls /etc/letsencrypt/live/sharefiles.kookbeach.com/ cert.pem chain.pem fullchain.pem privkey.pem README
Finally, the files "cert.pem", "chain.pem", and "privkey.pem" need to be copied to CATALINA_BASE/conf and the permission set correctly:
# cd /etc/letsencrypt/live/sharefiles.kookbeach.com # cp cert.pem /opt/tomcat/conf # cp chain.pem /opt/tomcat/conf # cp privkey.pem /opt/tomcat/conf # # chown tomcat:tomcat *.pemp chain.pem
Now, because the API/Download servers are a load balanced set of servers, this cert needs to be copied/sent to the other API/Download servers. Chris Bergeron says he would prefer we collect them in a central location for him to deploy. I'm hoping that is a straight-forward task the Java programmers at Backblaze can figure out. One idea is to store them in a private B2 bucket somewhere. If we did the "B2 IMPLEMENTATION CHOICE" for the VanityUrlMappingTable then we could store these in the following locations which WOULD make them available to BOTH Chris Bergeron AND ALSO the other API/Download servers:
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/sharefiles.kookbeach.com/certs/cert.pem
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/sharefiles.kookbeach.com/certs/chain.pm
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/sharefiles.kookbeach.com/certs/privkey.pem
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/downloads.larryphotography.com/cert.pem
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/downloads.larryphotography.com/chain.pm
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/downloads.larryphotography.com/certs/privkey.pem
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/tom-jones-meatpackers.com/certs/cert.pem
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/tom-jones-meatpackers.com/certs/chain.pm
https://f003.backblazeb2.com/file/bzvanityurlmapingtable/mappings/tom-jones-meatpackers.com/certs/privkey.pem
If this isn't clear, just ask BrianW to explain. BrianW can also describe several other different mechanisms that would work.
You should also make sure the Tomcat server.xml is set correctly, this is the part of the server.xml which looks like this:
<Connector port="443" protocol="org.apache.coyote.http11.Http11NioProtocol" maxThreads="150" SSLEnabled="true"> <SSLHostConfig> <Certificate certificateFile="conf/cert.pem" certificateKeyFile="conf/privkey.pem" certificateChainFile="conf/chain.pem" /> </SSLHostConfig> </Connector>
That's it! The next time Tomcat is restarted then this file can be fetched with SSL/HTTPS:
https://sharefiles.kookbeach.com/cutedogs/cute_puppy.jpg
Now, to start with we can wait until the Thursday push to
restart Tomcat, customers can just wait for it. Alternatively, we
could restart Tomcat on the API/Download servers of that particular cluster
once every two hours in a rotating fashion (restart the first API/Download
server's Tomcat, make sure it works and came back, and then restart the next
API/Download server, etc) IF AND ONLY IF one customer on that cluster has
added a vanity domain. This would pick up all the vanity domains that
had been added in that last two hours. I really don't expect customers
to be adding many of these, we're talking about maybe 100 vanity URLs in the
first year at most.
Refreshing the LetsEncrypt Certificates:
The LetsEncrypt certificates expire after 90 days, so they need to be
refreshed maybe once every 30 days. To refresh you just run the same
set of commands as the first time.
{kind=link}
{kind=link}
{kind=link}